CSV
- Let's look at an example
- weather data from the Austrian Zentralanstalt für Meteorologie und Geodynamik (ZAMG):
What is data?
What is a data format?
What data formats do you know?
What differences between data formats did you encounter?
Representation of data to encode and to store these data in a computer, and to transfer data between computers
character-encoded data ("text")
binary-encoded data
Unstructured, textual data:
Some useful Python libraries:
What is structured data? What is semi-structured data?
This is what the RFC 4180 says:
Unfortunately, these rules are not always followed "in the wild":
Johann Mitlöhner, Sebastian Neumaier, Jürgen Umbrich, and Axel Polleres. Characteristics of open data CSV files. In 2nd International Conference on Open and Big Data, August 2016.
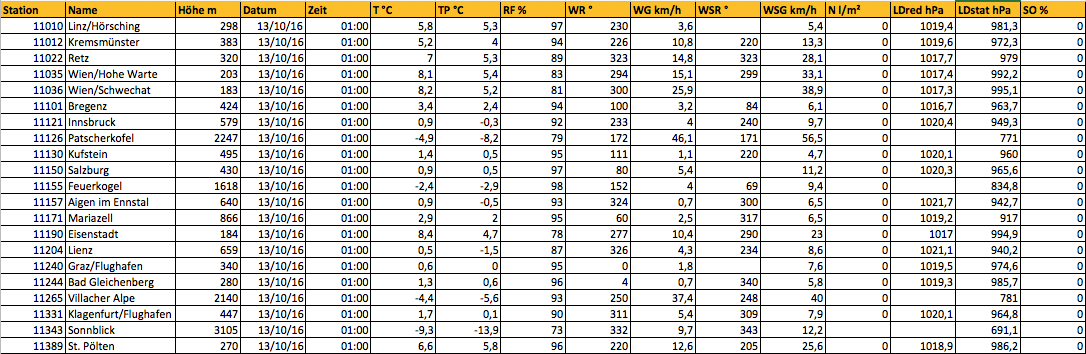
You find a CSV version of this data here: http://www.zamg.ac.at/ogd/
"Station";"Name";"Höhe m";"Datum";"Zeit";"T °C";"TP °C";"RF %";"WR °";"WG km/h";"WSR °";"WSG km/h";"N l/m²";"LDred hPa";"LDstat hPa";"SO %"
11010;"Linz/Hörsching";298;"13-10-2016";"01:00";5,8;5,3;97;230;3,6;;5,4;0;1019,4;981,3;0
11012;"Kremsmünster";383;"13-10-2016";"01:00";5,2;4;94;226;10,8;220;13,3;0;1019,6;972,3;0
11022;"Retz";320;"13-10-2016";"01:00";7;5,3;89;323;14,8;323;28,1;0;1017,7;979;0
11035;"Wien/Hohe Warte";203;"13-10-2016";"01:00";8,1;5,4;83;294;15,1;299;33,1;0;1017,4;992,2;0
11036;"Wien/Schwechat";183;"13-10-2016";"01:00";8,2;5,2;81;300;25,9;;38,9;0;1017,3;995,1;0
Question: What's NOT conformant to RFC 4180 here?
Potential issues:
<name>...</name>
Various "companion standards", e.g. schema languages:
Example from the entry tutorial:
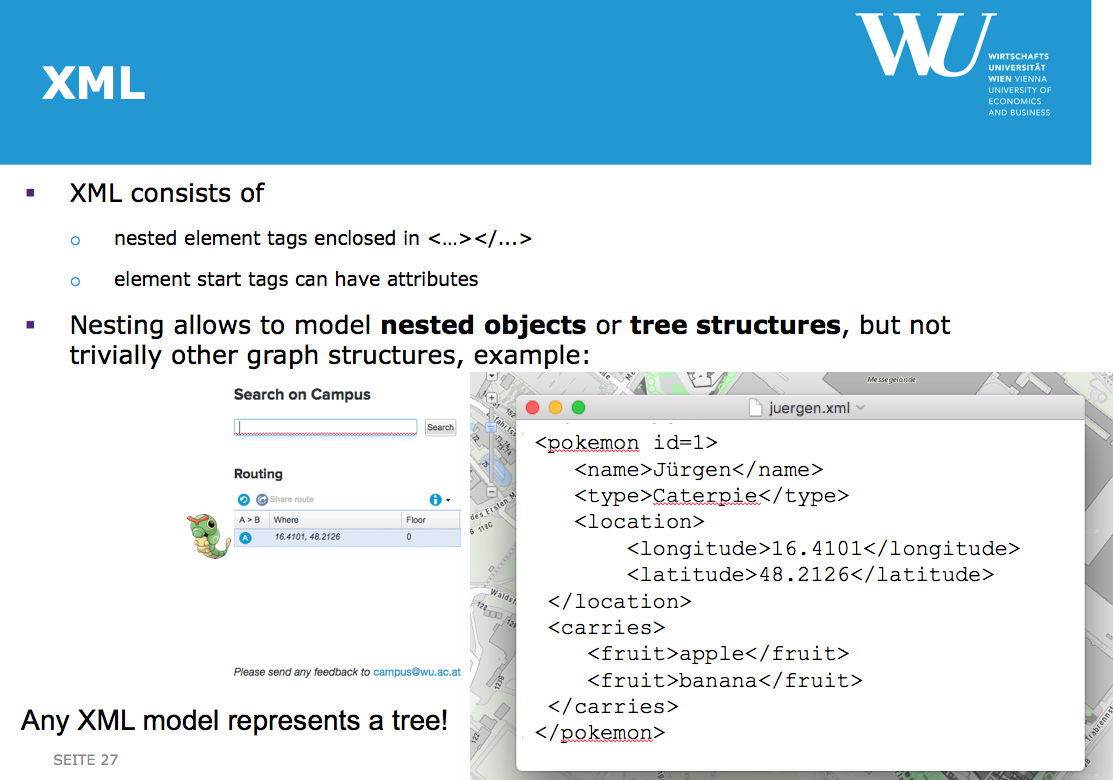
Potential issues: e.g.
Example:
{ "id": 10,
"firstname": "Alice",
"lastname": "Doe",
"active": true,
"shipping_addresses":
[ { "street": "Wonderland 1", "zip": 4711, "city": "Vienna", "country": "Austria", "home": true },
{ "street": "Welthandelsplatz 1", "zip": 1020, "city": "Vienna", "country": "Austria" },
{ "street": "MickeyMouseStreet10", "zip": 12345, "city": "Entenhausen", "country": "Germany" } ]
}
Example (vs. XML):
<customer id="10" active="true">
<firstname>Alice</firstname>
<lastname>Doe</lastname>
<shipping_addresses>
<address home = "true"><street>Wonderland 1</street><zip>4711</zip><city>Vienna</city><country>Austria</country></address>
<address><street>Welthandelsplatz 1</street><zip>1020</zip><city>Vienna</city><country>Austria</country></address>
<address><street>MickeyMouseStreet10</street><zip>12345</zip><city>Entenhausen</city><country>Germany</country></address>
</customer>
Jupyter notebooks are represented as JSON documents:
{
"cells": [
{
"cell_type": "markdown",
"source": [
"## Assignment 1\n",
"\n",
"This assignment is due on mm-dd-YYY-hh:mm by uploading the completed notebook at Learn@WU.\n",
"\n",
"### Task 1\n",
"\n"
Which access methods can be used to retrieve/download a dataset?
Datasets which have an URL (Web address) can be in general directly downloaded
Can all URLs be easily downloaded? If no, why?
Things to consider when downloading files.
NOTE: If you want to respect the robots.txt file, you need to first access the file (if available), inspect the allow/disallow rules and apply them to the URL you want to download.
http://data.wu.ac.at/robots.txt
User-agent: *
Disallow: /portalwatch/api/
Disallow: /portalwatch/portal/
Disallow: /portal/dataset/rate/
Disallow: /portal/revision/
Disallow: /portal/dataset/*/history
Disallow: /portal/api/
User-Agent: *
Crawl-Delay: 10
In this example, any robot is not allowed to access the specified sub-directories and any robot should wait 10 seconds between two requests
Some data sources can be only retrieved via Application Programming Interfaces (APIs).
Any reasons a data publisher would provide data access via an API rather than providing the data as files?
The reason for providing data access via an API:
The Last.fm API allows anyone to build their own programs using Last.fm data, whether they're on the Web, the desktop or mobile devices. Find out more about how you can start exploring the social music playground or just browse the list of methods below.
The Rotten Tomatoes API provides access to Rotten Tomatoes' ratings and reviews, allowing approved companies and individuals to enrich their applications and widgets with Rotten Tomatoes data.
The REST APIs provide programmatic access to read and write Twitter data. Author a new Tweet, read author profile and follower data, and more
ProgrammableWeb - an API directory for over 15K Web accessible APIs
The WU BACH API provide machine-readable data of WU's digital ecosystem in line with many OGD [1] initiatives.
e.g https://bach.wu.ac.at/z/BachAPI/courses/search?query=data+science
[
[
"18W",
"1629",
"Data Processing 1",
[
[
6947,
"Sobernig S."
],
[
12154,
"Polleres A."
],
[
16682,
"Hannak A."
]
]
]
/* ... */
]
1: Open Government Data
Web scraping is the act of taking content from a Web site with the intent of using it for purposes outside the direct control of the site owner. [source]
Typical scenarios for Web scraping: Collecting data on
Some examples:
Web scraping also requires to parse a HTML file using dedicated libraries.
WARNING: The legal ground for Web scraping is still not clear and we do not encourage or suggest to do Web scraping before checking if the homapage allows it . The legal topic of Web scraping will be covered in course III.
The following is the slide version of the notebook
In this part, we cover two data-access methods
We will also learn how to guess the file format by inspecting the metadata and the content of the retrieved data.
The typical steps involved in consuming data are:
The with statement is used to wrap the execution of a block with methods defined by a context manager.
This allows common try / catch / finally blocks to be encapsulated for convenient reuse.
Typical use-case : automatically ensure that streams are closed.
Other use cases: timing of functions, printing of logs at the end of a call
with COMMAND as C:
#work with C
Given that a file is stored on the local machine, we can access the file and inspect or load its content.
There are typically two ways to read the content of a file:
See also Chapter 7.2 in the Python 3 tutorial
We need the location of the file on disk to load its content.
An absolute file path points to the same location in a file system, regardless of the current working directory. To do that, it must include the root directory.
Windows: C:\Users\userName\data\course-syllabus.txt
Linux/Mac: /home/userName/data/course-syllabus.txt
A relative path points to the relative location of a file based on the given/current working directory.
Windows:
Linux: ~/data/course-syllabus.txt #starting from home directory
Linux: ../data/course-syllabus.txt #go one folder back, then into data
help( open )
Help on built-in function open in module __builtin__:
open(...)
open(name[, mode[, buffering]]) -> file object
Open a file using the file() type, returns a file object.
This is the preferred way to open a file.
See file.__doc__ for further information.
the function read consumes the entire contents of the file will be read and returned
filePath="./data/course-syllabus.txt"
#open file in read mode
f = open(filePath) # or open(filePath, 'r')
print("Full Output of content:")
content= f.read() # read the whole content and store it in variable content
print(content)
f.close() # do not forget to close the file
#better
with open(filePath) as f: # Carefully with indention and tabs
content = f.read()
print(content)
see also: ./src/openFile.py
Terminal> python3 ./src/openFile.py
Full Output of content:
This fast-paced class is intended for getting students interested in data science up to speed:
We start with an introduction to the field of "Data Science" and into the overall Data Science Process.
The primary focus of the rest of the course is on gaining fundamental knowledge for Data processing, ...
We will learn how to deal with different data formats and how to use methods and tools to integrate data from various sources, ...
This fast-paced class is intended for getting students interested in data science up to speed:
We start with an introduction to the field of "Data Science" and into the overall Data Science Process.
The primary focus of the rest of the course is on gaining fundamental knowledge for Data processing, ...
We will learn how to deal with different data formats and how to use methods and tools to integrate data from various sources, ...
The function readline consumes a single line from the file; a newline character (\n) is left at the end of the string
filePath="./data/course-syllabus.txt"
#open file in read mode
with open(filePath) as f:# or open(filePath, 'r')
print("first line: "+f.readline())
print("second line: "+f.readline())
print("third line: "+f.readline())
Terminal> python3 ./src/openFileReadLine.py
first line: This fast-paced class is intended for getting students interested in data science up to speed:
second line: We start with an introduction to the field of "Data Science" and into the overall Data Science Process.
third line: The primary focus of the rest of the course is on gaining fundamental knowledge for Data processing, ...
see also: ./src/openFileReadLine.py
filePath="./data/course-syllabus.txt"
#open file in read mode
with open(filePath) as f:# or open(filePath, 'r')
for line in f: # loop over every line in the file (separated by newline)
print(line)
Terminal> python3 ./src/openFileLoopLines.py
This fast-paced class is intended for getting students interested in data science up to speed:
We start with an introduction to the field of "Data Science" and into the overall Data Science Process.
The primary focus of the rest of the course is on gaining fundamental knowledge for Data processing, ...
We will learn how to deal with different data formats and how to use methods and tools to integrate data from various sources, ...
see also: ./src/openFileLoopLines.py
How can we guess the format of a file using as few resources as possible?
filePath="./data/course-syllabus.txt"
import os
fSize = os.path.getsize(filePath)
print('File size of'+filePath+' is: '+str(fSize) + ' Bytes') # typcasting of an int to str for str concatination
Terminal> python3 ./src/fileSize.py
File size of./data/course-syllabus.txt is: 435 Bytes
see also: ./src/fileSize.py
There exists many libaries in Python 3 to interact with Web resources using the HTTP protocol.
The HTTP protocol is the foundation of data communication for the World Wide Web
The current version of the protocol is HTTP1.1.
A client (browser or library) typically uses the HTTP GET operation to retrieve information about and the content of a HTTP URL.
First things first. We need to load the library to be able to use it
import urllib.request
Afterwards we need to open a connection to the HTTP Server and request the content of the URL
urllib.request.urlopen( URL )
import urllib.request
url="https://bach.wu.ac.at/z/BachAPI/courses/search?query=data+processing"
with urllib.request.urlopen(url) as f:
print(f.read())
Terminal> python3 ./src/urllib-load.py
b"[['18S', '5778', u'Data Processing 1', [[12631, u'Umbrich J.']]], ['18W', '1629', u'Data Processing 1', [[6947, u'Sobernig S.'], [12154, u'Polleres A.'], [16682, u'Hannak A.']]], ['18S', '5779', u'Data Processing 2: Scalable Data Processing, Legal & Ethical Foundations of Data Science', [[13928, u'Kirrane S.']]], ['18W', '1630', u'Data Processing 2: Scalable Data Processing, Legal & Ethical Foundations of Data Science', [[13928, u'Kirrane S.']]]]"
see also: ./src/urllib-load.py
First things first.
Afterwards we need to open a connection to the HTTP Server and request the content of the URL
import requests
requests.get( URL )
import requests
url="https://bach.wu.ac.at/z/BachAPI/courses/search?query=data+processing"
r = requests.get( url )
content=r.text
print(content)
Terminal> python3 ./src/requests-load.py
[['18S', '5778', u'Data Processing 1', [[12631, u'Umbrich J.']]], ['18W', '1629', u'Data Processing 1', [[6947, u'Sobernig S.'], [12154, u'Polleres A.'], [16682, u'Hannak A.']]], ['18S', '5779', u'Data Processing 2: Scalable Data Processing, Legal & Ethical Foundations of Data Science', [[13928, u'Kirrane S.']]], ['18W', '1630', u'Data Processing 2: Scalable Data Processing, Legal & Ethical Foundations of Data Science', [[13928, u'Kirrane S.']]]]
see also: ./src/requests-load.py
How can we guess the format of the content of a URL?
Every HTTP operation has a HTTP request and response header.
HTTP/1.1 200 OK
Date: Wed, 12 Oct 2016 12:39:12 GMT
Server: Apache/2.4.18 (Ubuntu) mod_wsgi/4.3.0 Python/2.7.12
Last-Modified: Wed, 12 Oct 2016 07:29:32 GMT
ETag: "1b3-53ea5f4498d97"
Accept-Ranges: bytes
Content-Length: 435
Vary: Accept-Encoding
Content-Type: text/plain
See also the corresponding RFC. Interesting header fields: Content-Type and Content-Length
Python3 is case-sensitive, meaning that "Content-Type" != "content-type". Sometimes, header fields might be in lower-case or capitalized
import urllib.request
url="https://bach.wu.ac.at/z/BachAPI/courses/search?query=data+processing"
req = urllib.request.Request( url , method="HEAD") # create a HTTP HEAD request
with urllib.request.urlopen(req) as resp:
header = resp.info()
# print the full header
print("Header:")
print(header)
## print the content-type
print("Content-Type:")
print(header['Content-Type'])
## print the content-type
print("Content-Length in Bytes:")
print(header['Content-Length'])
Terminal> python3 ./src/urllib-header.py
Header:
Date: Sun, 04 Nov 2018 21:41:47 GMT
Server: Zope/(2.13.23, python 2.7.9, linux2) ZServer/1.1
Set-Cookie: BACH_PRXY_ID=W99nm5UM7@7465DEOMkybAAAAAE; path=/; domain=.wu.ac.at; expires=Wed, 01-Nov-2028 21:41:47 GMT
Set-Cookie: BACH_PRXY_SN=W99nm5UM7@7465DEOMkybAAAAAE; path=/; domain=.wu.ac.at
Last-Modified: Wed, 29 Sep 2010 07:54:06 GMT
Accept-Ranges: none
Content-Type: application/octet-stream
Content-Length: 381
Via: 1.1 bach.wu.ac.at
X-XSS-Protection: 1; mode=block
X-Frame-Options: SAMEORIGIN
X-Content-Type-Options: nosniff
Connection: close
Content-Type:
application/octet-stream
Content-Length in Bytes:
381
see also: ./src/urllib-header.py
import requests
url="https://bach.wu.ac.at/z/BachAPI/courses/search?query=data+processing"
r = requests.head( url ) # would also work with a HTTP Get
headerDict=r.headers
print(headerDict)
Terminal> python3 ./src/requests-header.py
{'Date': 'Sun, 04 Nov 2018 21:41:47 GMT', 'Server': 'Zope/(2.13.23, python 2.7.9, linux2) ZServer/1.1', 'Set-Cookie': 'BACH_PRXY_ID=W99nm9Q-D@p@TgflM-YG5gAAAEo; path=/; domain=.wu.ac.at; expires=Wed, 01-Nov-2028 21:41:47 GMT, BACH_PRXY_SN=W99nm9Q-D@p@TgflM-YG5gAAAEo; path=/; domain=.wu.ac.at', 'Last-Modified': 'Wed, 29 Sep 2010 07:54:06 GMT', 'Accept-Ranges': 'none', 'Content-Type': 'application/octet-stream', 'Content-Length': '381', 'Via': '1.1 bach.wu.ac.at', 'X-XSS-Protection': '1; mode=block', 'X-Frame-Options': 'SAMEORIGIN', 'X-Content-Type-Options': 'nosniff', 'Connection': 'close'}
see also: ./src/requests-header.py
import requests
url="http://datascience.ai.wu.ac.at/ss17_datascience/data/course-syllabus.txt"
r = requests.head( url ) # would also work with a HTTP Get
headerDict=r.headers
#>
#print all available response header keys
print("Header")
print(headerDict)
#access content-type header
if "Content-Type:" in headerDict:
print("Content-Type:")
print( headerDict['Content-Type'] )
Terminal> python3 ./src/requests-header-inspect.py
Header
{'Date': 'Sun, 04 Nov 2018 21:41:47 GMT', 'Server': 'Apache/2.4.29 (Ubuntu)', 'Location': 'https://datascience.ai.wu.ac.at/ss17_datascience/data/course-syllabus.txt', 'Keep-Alive': 'timeout=5, max=100', 'Connection': 'Keep-Alive', 'Content-Type': 'text/html; charset=iso-8859-1'}
see also: ./src/requests-header-inspect.py
Why is that occurring? "J�rgen"
How can you find interesting datasets for your project?
Many datasets can be found using a Web Search engine such as Google, Bing or Yahoo
Combine your keyword search with tokens such as "csv", ".csv".
Such search engines offer also more advanced search features to filter for particular data formats
Fileformat search on Bing and Yahoo does not return very good results
Quora and Stackoverflow are question-and-answer sites where people can pose any question and receive community answers
Some direct links:
The popular useful platform change over time. Hint: Follow Metcalfe's Law
Some general datascience blogs regularly have posts about datasets
Lists of datascience blogs:
Many people also provide a curated lists of public datasets or APIs to datasets. These lists can be typically found via a Google/Bing/Yahoo Search
Some examples:
So called (Open Data) portals are catalogs for datasets.
Further links:
What should you consider if you use "public" datasets
Public does not necessarily mean free
Many public datasets come with certain restrictions of what one is allowed to do with the data.
The data license ( if available) typically specifies the following questions:
More about licenses of datasets in SBWL3