Data Formats, Encoding & Access
Axel Polleres
Stefan Sobernig
October 12, 2021
Possible views on data
- Type and scales: numerical (example), categorical (example), or binary (example)
- Text types, e.g.: Emails, tweets, newspaper articles
- Records: user-level data, timestamped event data (e.g.: log files)
- Geo-location data
- Relationship and communication data (Email conversations)
- Sensor data (e.g., streams in Course III)
- Resource types: images, audio, video (not covered in this lecture)
- ...
Data formats
Question.
What is a data format?
What data formats do you know?
What differences between data formats did you encounter?
Data (exchange) formats
- Data is stored in many different representations (for different purposes):
- Data structures (typically volatile, i.e. an internal representation of data is in your computer's memory (RAM), to process it efficiently)
vs.
- Data exchange format (typically persistent, i.e., a serialisation of data to store, archive, or exhange data)
- Further, data you want to analyze as data scientist is often only available
- in different formats, and
- across different systems & sources,
- with different access mechanisms.
- Some formats are intended to be read and consumed by humans, other by machines
Data (exchange) formats
For data exchange formats (representation of data to encode and to store these data in a
computer, and to transfer/exchange data between computers) we further distinguish
character-encoded data ("text")
- plain (unstructured) text files ( \*.txt)
- semi-structured data in text files
- structured data in text files
directly binary-encoded data (0s and 1s)
- images, audio, video
- binary encoding of structured data
Character-encoded, unstructured text data
Unstructured, textual data:
- May be hidden inside other formats and needs to be extracted, e.g.:
- plain-text mails hidden in mailbox archives .mbox format (RFC4155)
- plain text from a PDF file
- plain text from a HTML page
Some useful Python libraries:
Character-encoded, (semi-)structured data
Question.
What is structured data?
What is semi-structured data?
Character-encoded, (semi-)structured data
- Structured data adheres to a particular data definition (a.k.a. "data schema")
- typically tabular (sets of records as rows of a table)
- often exchanged using comma-separated values (CSV )
- Semi-structured data is structured data that does not (fully) conform to a schema
- typically represented by (nested) objects or sets of nested attribute-value pairs
- exchange formats for semi-structured data are XML and JSON
- Graph-structured data
- a common standard exchange format is: RDF /Turtle
- Beware: The boundaries are blurry ... (e.g. there's a JSON
serialisation for RDF, called JSON-LD, etc.)
CSV
- Standard defined in RFC 4180
- CSV and its dialects have been in widespread use since the 1960s, but only became standardised in 2005
This is what the RFC 4180 says:
- "Within the header and each record, there may be one or more fields, separated by commas."
- "Each line should contain the same number of fields throughout the file."
- "Each field may or may not be enclosed in double quotes"
- "Each record is located on a separate line, delimited by a line break (CRLF)."
Unfortunately, these rules are not always followed "in the wild":
Johann Mitlöhner, Sebastian Neumaier, Jürgen Umbrich, and Axel Polleres. Characteristics of open data CSV files. In 2nd International Conference on Open and Big Data, August 2016.
CSV
- Let's look at an example
- weather data from the Austrian Zentralanstalt für Meteorologie und Geodynamik (ZAMG):
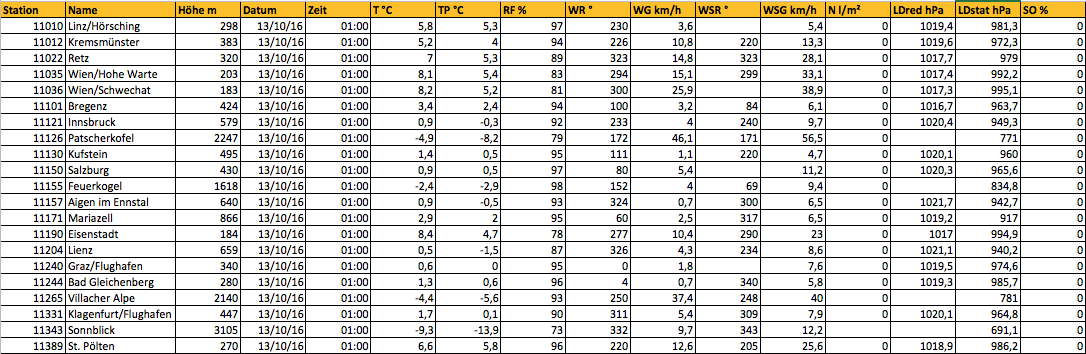
CSV
You find a CSV version of this data here: http://www.zamg.ac.at/ogd/
"Station";"Name";"Höhe m";"Datum";"Zeit";"T °C";"TP °C";"RF %";"WR °";"WG km/h";"WSR °";"WSG km/h";"N l/m²";"LDred hPa";"LDstat hPa";"SO %"
11010;"Linz/Hörsching";298;"13-10-2016";"01:00";5,8;5,3;97;230;3,6;;5,4;0;1019,4;981,3;0
11012;"Kremsmünster";383;"13-10-2016";"01:00";5,2;4;94;226;10,8;220;13,3;0;1019,6;972,3;0
11022;"Retz";320;"13-10-2016";"01:00";7;5,3;89;323;14,8;323;28,1;0;1017,7;979;0
11035;"Wien/Hohe Warte";203;"13-10-2016";"01:00";8,1;5,4;83;294;15,1;299;33,1;0;1017,4;992,2;0
11036;"Wien/Schwechat";183;"13-10-2016";"01:00";8,2;5,2;81;300;25,9;;38,9;0;1017,3;995,1;0
CSV
Question: What's NOT conformant to RFC 4180 here?
Potential issues:
- different delimiters
- lines with different numbers of elements
- header line present or not
Another example: https://info.gesundheitsministerium.at/opendata/ --> Try to download timeline-bbg.csv and open it with Microsoft Excel...
XML
- eXtensible Markup Language, a W3C standard
- Evolved from the Standard Generalized Markup Language (SGML)
- Semi-structured data, with structured portions taking the shape of a tree of meta-data (annotation) elements.
- consisting of elements, delimited by named start and end tags
<name>...</name>
- with one root element
- arbitrary nesting
- start tags can additionally carry attributes
- unstructured data are represented as text nodes
Various "companion standards", e.g. schema languages:
XML
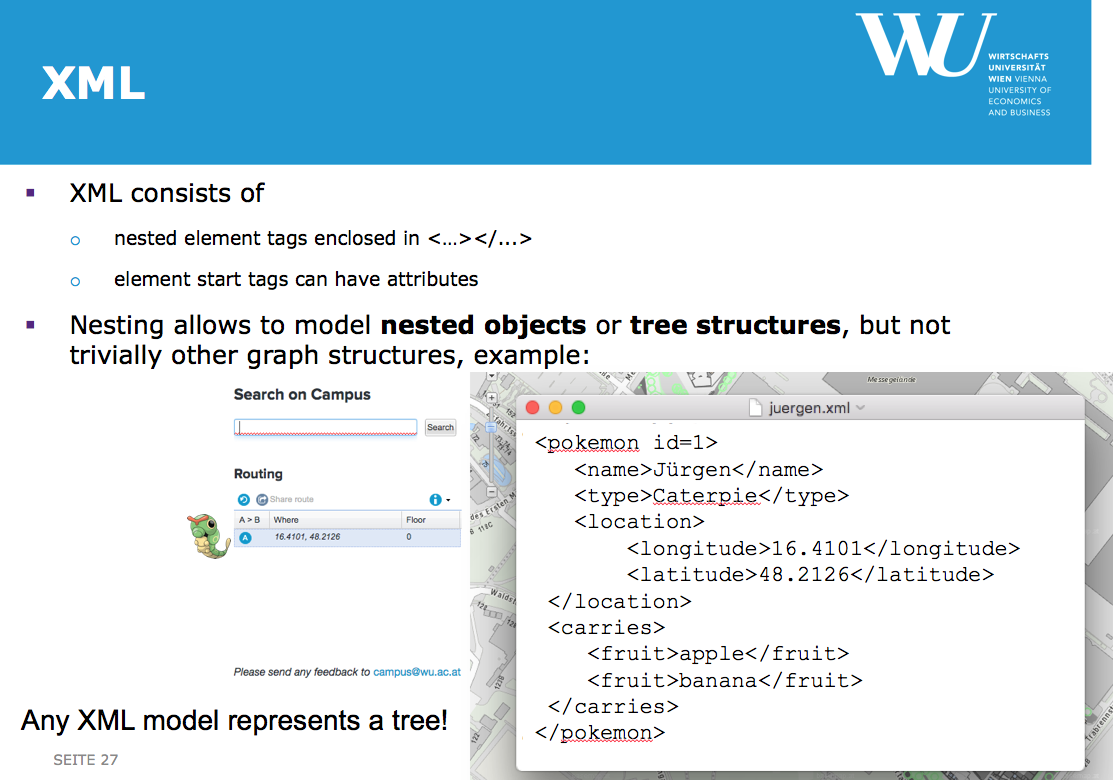
Example from the entry tutorial:
<pokemon id=1>
<name>Jürgen</name>
<type>Caterpie</type>
<location>
<longitude>16.4101</longitude>
<latitude>48.2126</latitude>
</location>
<carries>
<fruit>apple</fruit>
<fruit>banana</fruit>
</carries>
</pokemon>
XML
Potential issues: e.g.
- broken nesting: non-closed tags
- syntax: missing quotes in attributes, ambiguous meaning of special characters
- there are (mostly educational) online-validators:
JSON
- JavaScript Object Notation (JSON)
- an unordered set of key-value pairs of data
- A JSON Object is enclosed in { }.
- Keys and values separated by :
- Key value-pairs are separated by ,
- JSON objects can be nested, i.e. values can again be objects.
- arrays (i.e. ordered collections of values) are enclosed in '[' ']'.
JSON
Example:
{ "id": 10,
"firstname": "Alice",
"lastname": "Doe",
"active": true,
"shipping_addresses":
[ { "street": "Wonderland 1", "zip": 4711, "city": "Vienna", "country": "Austria", "home": true },
{ "street": "Welthandelsplatz 1", "zip": 1020, "city": "Vienna", "country": "Austria" },
{ "street": "MickeyMouseStreet10", "zip": 12345, "city": "Entenhausen", "country": "Germany" } ]
}
JSON
Example (vs. XML):
<customer id="10" active="true">
<firstname>Alice</firstname>
<lastname>Doe</lastname>
<shipping_addresses>
<address home = "true"><street>Wonderland 1</street><zip>4711</zip><city>Vienna</city><country>Austria</country></address>
<address><street>Welthandelsplatz 1</street><zip>1020</zip><city>Vienna</city><country>Austria</country></address>
<address><street>MickeyMouseStreet10</street><zip>12345</zip><city>Entenhausen</city><country>Germany</country></address>
</customer>
JSON
Jupyter notebooks are represented as JSON documents:
{
"cells": [
{
"cell_type": "markdown",
"source": [
"## Assignment 1\n",
"\n",
"This assignment is due on mm-dd-YYY-hh:mm by uploading the completed notebook at Learn@WU.\n",
"\n",
"### Task 1\n",
"\n"
...
JSON
- JSON often used in Web applications to transfer JavaScript objects between server-side and client-side application
- ... JSON has become the most common format for Web APIs
- There is also a schema-definition language for JSON
- Example online validator (again, rather for small/educational examples): jsonlint.com
Summary: Character-encoded, (semi-)structured data
- Structured data adhering to a particular (tabular) schema can be represented as comma-separated values lists (CSV)
- Semi-structured data is a form of structured data that does not conform with a fixed schema: (XML, JSON)
- Outlook: graph-structured data can be represented using standardised data formats (RDF; Turtle; Property Graphs)
- On the one hand, CSV, XML, RDF can be seen as just different serialisation formats of data.
- On the other hand, they employ different characteristic, abstract data structures (event-oriented vs. document-oriented APIs).
- There are diffferent tools (and Python libraries!) for dealing with these formats and their variants.
- programms that check the syntax of a structured data format for validity are called parsers
- we have seen some User Interfaces and Web tools (e.g. CSV Lint or JSONLint), but you can also use Python for that!
Excursus/repition: Character Encodings
Character-encoded data, is encoding data in text made upd from a character set, which is encoded into 0s and 1s,
- different such character sets exist
- different encodings exist for each character set:
Question.
Why is that occurring? "J�rgen likes to eat K�rntner K�snudln"
Excursus/repition: Character Encodings
- Symbols (=characters) are encoded in bits and bytes differently, depending on the number of characters in the overall symbol set:
- ASCII character set needs only 7 bits for its 128 characters (typically uses 1 byte, i.e. 8 bit encoding) .
- Unicode uses up to 4 bytes (the common UTF-8 encoding uses variable length of 1-4 bytes)
- Other character encodings for German texts used e.g. in older windows versions: ISO/IEC 8859-15 (aka LATIN-9)
- Assuming a wrong encoding when reading a character-encoded data, or using software tools that cannot handle the input encoding correctly produces arifacts like the one in the last slide.
Excursus: Binary encoding of structured data
- For most structured data formats there are also binary (often compressed) binary formats, examples:
- XML: EXI (Efficient XML Interchange format)
- compressed, binary XML interchange format
- a W3C standard recommendation
- JSON: BSON (Binary JSON)
- RDF: HDT (Headers-Dictionary-Triples)
- a binary, compressed RDF serialization, partially inspired by EXI
- W3C member submission
- Co-developed by our institute!
Notebook for Accessing Data: the Python Way
02_Encodings+and+reading+text+files.ipynb in Jupyter's unit2 subfolder
03_Data_Formats_and_Standards.ipynb in Jupyter's unit2 subfolder
Ways to access and get data
Question.
Which access methods can be used to retrieve/download a dataset?
Ways to access and get data
From a file on disk:
- depending on your operating system, different file paths format, e.g.
-
C:\Users\apollere\Documents\myFile.txt
-
/home/users/apollere/myfile.txt
- or, relative paths
./data/myfile.txt
From the Web:
- Download the dataset directly via a URL
- Access the dataset via a API
- Scraping the data from a HTML page
Downloading data
Datasets which have an URL (Web address) can be in general directly downloaded
- either manually by pointing the browser to the URL and saving it
- or using programs which access the content and download it to disk or memory
The underlying protocol is called Hypertext Transfer Protocol (HTTP), nowadays typically HTTP1.1
Let's see how HTTP works
Downloading data
Question.
Can all URLs be easily downloaded? If no, why?
Downloading data
Things to consider when downloading files.
- Some URLs require authentication (we do not cover that case in the lecture)
- simplest mechanism: .htaccess ,
- typically more sophisticated methods used nowadays (OAUTH)
- Robots.txt protocol
- A protocol to guide machines what they are allowed to access
- if existing, located at http://DOMAIN/robots.txt
- Robots/Machines can ignore this protocol.
NOTE: If you want to respect the robots.txt file, you need to first access the file (if available),
inspect the allow/disallow rules and apply them to the URL you want to download.
Robots.txt
- Defines which URL sub-directory are allowed or disallowed to be accessed and by whom (User-agent)
- Also allows to recommend a so called crawl-delay ( time span between to consecutive accesses)
Robots.txt: Example
http://data.wu.ac.at/robots.txt
User-agent: *
Disallow: /portalwatch/api/
Disallow: /portalwatch/portal/
Disallow: /portal/dataset/rate/
Disallow: /portal/revision/
Disallow: /portal/dataset/*/history
Disallow: /portal/api/
User-Agent: *
Crawl-Delay: 10
In this example, any robot is not allowed to access the specified sub-directories and any robot should wait 10 seconds between two requests
Accessing data via API
Some data sources can be only retrieved via Application Programming Interfaces (APIs).
Question.
Any reasons a data publisher would provide data access via an API rather than providing the data as files?
Accessing data via API
The reason for providing data access via an API:
- the data is generated dynamically/on-demand (e.g. current temperature)
- access control (APIs are usually only accessible with access credentials):
- who is accessing data and from where
- how often someone can access the data ( to avoid overloading the server)
- fine grained access to data
- all weather information for a certain location vs. downloading GB of global weather data
- easier integration into an existing Application
Accessing data via API: Examples
Last.fm
The Last.fm API allows anyone to build their own programs using Last.fm data, whether they're on the Web, the desktop or mobile devices. Find out more about how you can start exploring the social music playground or just browse the list of methods below.
Twitter
The REST APIs provide programmatic access to read and write Twitter data. Author a new Tweet, read author profile and follower data, and more
(not entirely) Open Weatherdata
a JSON API for easy access of current weather, freemium model (e.g., historic data is not free)
ProgrammableWeb - an API directory for over 20K Web accessible APIs
Accessing data via a Distributed System API
- Many APIs require authentication and apply a rate limit ( how many access per time span)
- Specific access methods/protocols (library and protocol)
- typically requires registration via an API key
- Protocol: There exists different access protocols
- libraries: Typically provide functions that hide the underlying access mechanisms
- Returned data format is typically negotiable (JSON, generic or specific_XML_)
- List of Python API's
Scraping Web data
Web scraping is the act of taking content from a Web site with the intent of using it for purposes outside the direct control of the site owner. [source]
Typical scenarios for Web scraping: Collecting data on
- real estate,
- eCommerce, or
- travel pages
Some examples:
Web scraping also requires to parse a HTML file using dedicated libraries.
WARNING: The legal ground for Web scraping is often not clear and we do not encourage or suggest to do Web scraping before checking if the site allows it.
Legal topics around Web scraping will be covered in course III.
Accessing Data: the Python Way
Notebook for Accessing Data: the Python Way
01_Accessing-Data.ipynb in Jupyter's unit2 subfolder
Let's look at the notebooks now!
Excursus: How and where to find data?
Question
Question.
How can you find interesting datasets for your project?
Possible ways to find data
- Search online using Google, Bing, Yahoo
- Follow questions/search on Quora, Stackoverflow,...
- Blogs about datascience
- Curated lists of datasets
- Twitter ('#dataset' '#opendata')
- Data portals
Google, Bing, etc.
Many datasets can be found using a Web Search engine such as Google, Bing, etc.
Combine your keyword search with tokens such as "csv", ".csv".
Such search engines offer also more advanced search features to filter for particular data formats
Fileformat search does not return very good results on all search engines, unfortunately.
(Try out e.g.: 'WU Vienna Lectures')
Follow questions/search on Quora, Stackoverflow, Reddit
Quora and Stackoverflow are question-and-answer sites where people can pose any question and receive community answers
Some direct links:
Notice.
The popular useful platform change over time. Hint: Follow Metcalfe's Law
Blogs about datascience
Some general datascience blogs regularly have posts about datasets
Lists of datascience blogs:
Curated lists of datasets
Many people also provide a curated lists of public datasets or APIs to datasets.
These lists can be typically found via a Google/Bing/Yahoo Search
Some examples:
Open Data Portals
So called (Open Data) portals are catalogs for datasets.
Further links:
Question
Question.
What should you consider if you use "public" datasets
Consuming "public" datasets
Public does not necessarily mean free
Many public datasets come with certain restrictions of what one is allowed to do with the data.
The data license ( if available) typically specifies the following questions:
- Is it allowed to reuse the data in my project/application?
- Is it allowed to merge the dataset with other datasets?
- If it is allowed, with what other licenses can the data be merged
- Is it allowed to modify the dataset (e.g. remove or transform values)?
Notice.
More about licenses of datasets in SBWL3
Homework
- Find two datasets in different formats online (one CSV and one JSON or XML)
- Write code to detect the file format and file size (using Python)
- Validate the data sets according to the deteced file format (you can use an online validation service)
- Find out and describe characteristics of the datasets (depending on the file format), again using Python:
- JSON: number of different attribute names, nesting depth, length of the longest list appearing in an attribute value.
- XML: number of different element and attribute names, nesting depth, maximum number of child nodes in any element (including the root element)
- CSV: number of columns, number of rows, column number (from 0 to n) of the column which contains the longest text
Details: Assignment 2 will be published on learn by tomorrow latest
Submission: Via Assignment 2 on Learn@WU (deadline will be exactly 2 weeks from publication).
←
→